
Hvor god er egentlig datamaskinen til å gjette hvordan jeg har lagd de kunstige datasettene mine?
Jeg har tidligere skrevet om hvordan jeg har gått frem for å lage kunstige astronomiske data til masteroppgaven min, hvor jeg beskrev hvilke komponenter som skal til for å lage lysspektre for aktiv galakser som er rimelig realistiske. Hva som kan sies å være realistisk, er basert på faktiske observasjoner. Selve poenget med å lage kunstige datasett er at når jeg lager data fra «scratch», vet jeg nøyaktig hvor mye det er av de ulike komponentene som gjør at dataene ser ut slik som de gjør. Nå har jeg skrevet et dataprogram som skal forsøke å gjette hvor mye det er av de ulike komponentene ved å modellere spektrene jeg har lagd. Tror du den får det til?
Hva er det egentlig datamaskinen skal prøve på?
I masteroppgaven min ser jeg på lysspektre fra aktive galakser. Et lysspektrum er en graf som viser hvor mye lys et objekt sender ut i de ulike bølgelengdene. Ett av spektrene jeg har lagd ser for eksempel slik ut:

Mitt kunstige aktiv galakse-spektrum for en bestemt konfigurasjon av parametre. Den horisontale aksen viser bølgelengder målt i Ångstrøm, mens den vertikale aksen viser fluks, et mål på hvor mye lys som sendes ut av et objekt.
Den svarte kurven viser summen av alle komponentene (vist i diverse farger) og representerer det kunstige spekteret. Det som skal skje nå, er at basert på kun den sorte kurven, skal modelleringsprogrammet mitt prøve å gjette hvor mye de ulike fargede komponentene bidrar for å lage nettopp et slikt spektrum!
Modelleringsprogrammet jeg har skrevet er veldig enkelt – så enkelt som det kan få blitt! Programmet får vite oppskriften jeg har brukt for å lage det kunstige spekteret, men ikke de eksakte tallene jeg har brukt. Se for eksempel på den lilla linjen i grafen ovenfor: Den er representert ved formelen F = C · λ K, hvor K bestemmer stigningen på kurven, og C bestemmer hvor høyt på y-aksen kurven skal ligge (λ representerer bølgelengden). Modelleringsprogrammet får vite formelen, men ikke hva verdien til K og C er. Det må den prøve å finne ut av selv. Totalt sett skal den finne frem til 11 forskjellige verdier som er med på å bestemme hvordan spekteret ser ut. Jeg har selv bestemt hvilke verdier den skal finne, og kunne valgt enda flere, men jo fler jeg velger, desto mer komplisert og tidkrevende blir det for programmet å finne verdiene.
Måten datamaskinen gjetter seg frem til disse verdiene på, er ved at jeg først gir den noen startverdier, som selvfølgelig ikke er de riktige verdiene. Deretter endrer programmet bittelitt på disse verdiene for å prøve å minimere forskjellen mellom den modellerte kurven og den faktiske kurven den skal prøve å finne. Slik fortsetter programmet å justere verdiene litt etter litt, frem til den føler at den har funnet en bra tilnærming til den faktiske kurven (på programmeringsspråk sier man at programmet går gjennom flere iterasjoner). Men hvordan vet programmet når den skal være fornøyd med resultatet?
Litt hjelp på veien
I blant sier datamaskinen seg fornøyd med et resultat jeg overhode ikke kan skjønne at den er fornøyd med, for resultatet ser ikke ut! Her er noen av de mest sjokkerende resultatene, hvor kurven i rosa representerer kurven som modelleringsprogrammet har regnet seg frem til (trykk for å se større):
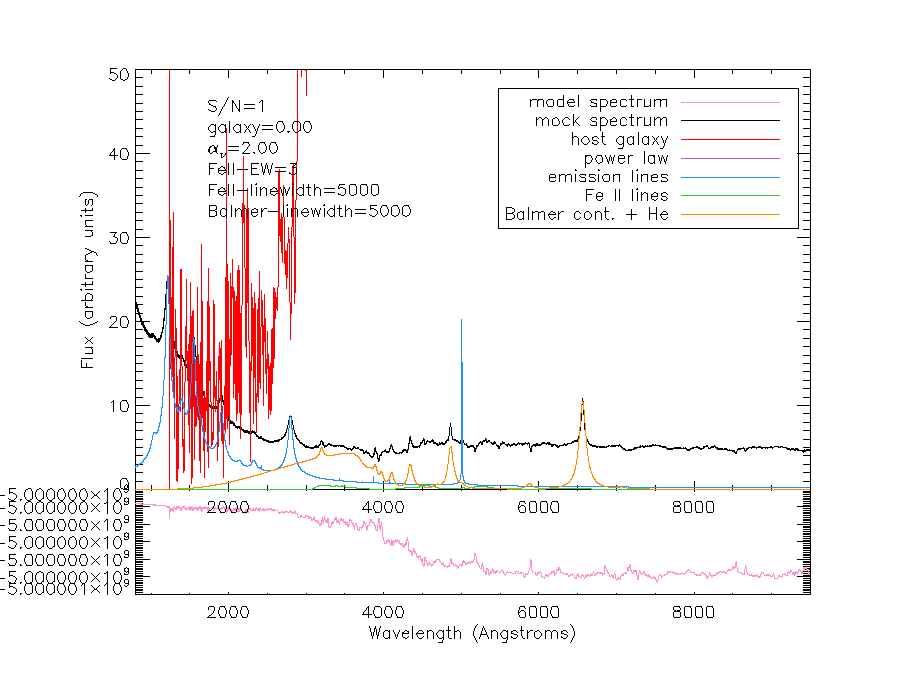

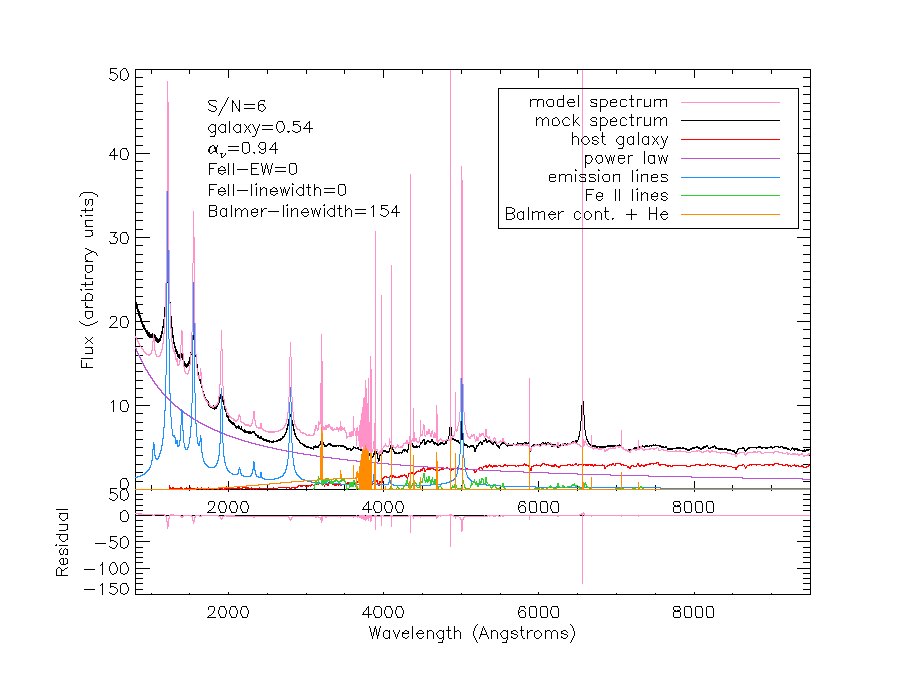
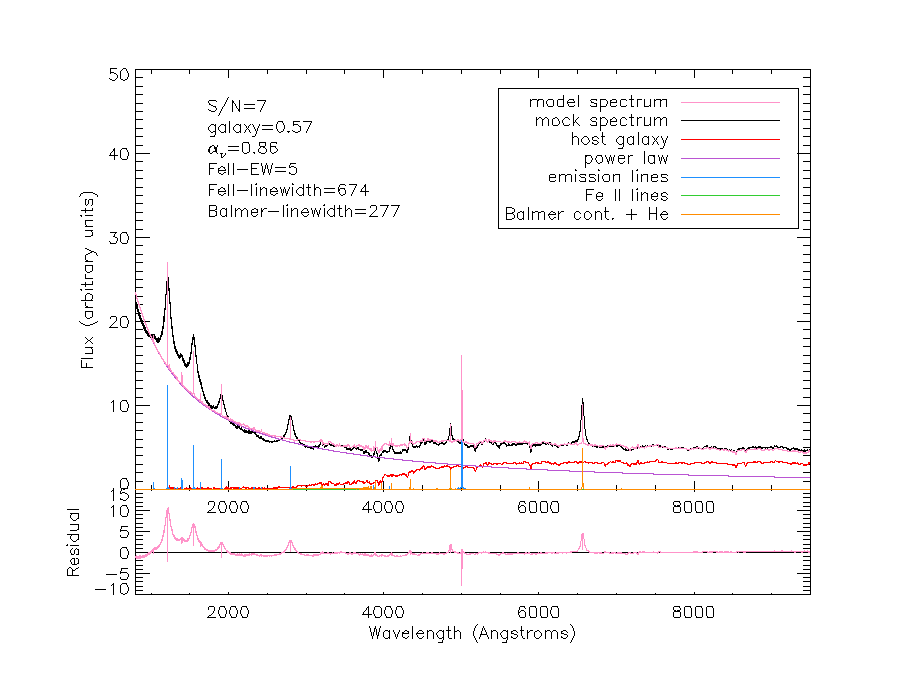
Jeg ville aldri stolt på resultatene fra modelleringer som ser slik ut, for det er åpenbart at programmet ikke har funnet en god tilnærming til den faktiske kurven. Det lille plottet under hovedplottet som er merket «Residuals» viser avviket mellom modellen og det faktiske spekteret. Den skal ideelt sett være nærmest mulig null for alle bølgelengder, noe den er svært langt ifra å være i noen av disse tilfellene.
Det er to grunner til at programmet sier seg fornøyd: Den relative forskjellen i estimatene fra én iterasjon til den neste er mindre enn 10-10, eller endringen i residualene er mindre enn 10-10 fra én iterasjon til den neste. Men det trenger jo ikke nødvendigvis bety noe som helst, når vi ser på eksemplene ovenfor.
I blant prøver og prøver modelleringsprogrammet uten å få det til. Selv om datamaskinen har fått en nokså enkel oppgave (syns jeg!), trenger den altså likevel litt hjelp på veien. Så da sjekker jeg om det er kommandoer jeg kan legge inn i programmet mitt som kan gjøre programmet litt smartere. Jeg kan heldigvis hjelpe den litt ved å gjøre noen enkle grep:
- Startverdier: Hvor god maskinen er til å gjette de riktige verdiene, kommer an på hvilke verdier jeg lar den starte med. Noen gang kan programmet forville seg helt dersom jeg har gitt den et dårlig utgangspunkt. Men det er ikke nødvendigvis slik at det samme utgangspunktet vil være dårlig for alle de forskjellige spektrene. Derfor lar jeg programmet trekke startverdier tilfeldig fra en liste med mulige startverdier som jeg selv har definert. Da sikrer jeg meg dessuten mot at resultatene fra alle kjøringene er avhengig av hva startverdiene var, ettersom de vil variere litt fra gang til gang (les om bias).
- Maks antall iterasjoner: Jeg har bestemt at programmet mitt skal få 200 forsøk på å finne en kurve som passer spekteret den skal tilpasse seg. Programmet trenger sjeldent så mange forsøk. Når den gjør det, er det ofte et tegn på at den sliter og ikke vil få det til uansett om den hadde fått flere forsøk. Dersom grensen på 200 iterasjoner er nådd, kan jeg ikke bruke resultatene programmet gir meg, for den var jo egentlig ikke ferdig. Da lar jeg programmet prøve på nytt med andre startverdier til det samme spekteret. Jeg har bestemt at den kan få trekke nye startverdier ti ganger. Programmet trenger veldig sjeldent så mange forsøk. Dersom den skulle gjøre det, gir jeg opp nettopp det spekteret, og fortsetter med neste spekteret i listen. Det får jo være grenser 🙂
- Minimering av χ2: Det finnes et tall som beskriver hvor nærme modellen ligger det faktiske spekteret, og det er χ2 («chi-squared»). For hver modellering blir dette tallet regnet ut av programmet. Og det er her nøkkelen for å luke ut de forferdelige resultatene ligger: Denne verdien skal nemlig helst være minst mulig. Ved å se på χ2-verdien til de åpenbart dårlige resultatene (som vist ovenfor), og de tilsynelatende gode resultatene (som vist nedenfor), kommer det frem at det er et markant skille i verdien til χ2 for disse to grupperingene. Da er det enkelt å legge inn en test i programmet som sier at dersom χ2 er høyere enn en viss grenseverdi, skal programmet prøve på nytt med nye startverdier. Det gjør en enorm forskjell for hvor bra resultatene blir! 😀
Når det funker
Det hender (heldigvis!) at programmet treffer «spot on» – enten av seg selv, eller med litt tvungen hjelp fra meg som beskrevet ovenfor – og klarer å produsere et spektrum som ser ut til å matche spekteret jeg ga det mer eller mindre perfekt. Slik som dette:

Et eksempel på en temmelig vellykket modellering av et spekter. Programmet sliter med å modellere en bestemt linje, nærmere bestemt [O ııı]-linjen (dobbelt-ionisert oksygen) som befinner seg ved en bølgelengde på 5007 Å, som peker seg tydelig ut i residualplottet nederst. Akkurat denne linjen er spesiell, for den blir ikke estimert av programmet, men blir kalkulert av resultatet fra noen andre verdier som programmet skal finne. Så dersom programmet ikke har funnet bra nok estimater for disse verdiene, vil det reflekteres i nettopp denne linjen.
Planen videre
Det jeg holder på å gjøre nå, er å kjøre maaange modelleringer (nærmere bestemt 250 stykker) av hver type spekter, hvor én type spekter er et spekter med en bestemt kombinasjon av verdier. Det betyr at de 250 versjonene av én type spekter vil være så godt som identiske, men støyet som er lagt til spekteret vil være bittelitt forskjellig fra spekter til spekter.
Deretter skal jeg lage histogrammer som viser hvilke verdier modelleringsprogrammet har estimert for de 250 marginalt ulike spektrene, for å se hvor stor spredningen i estimatene er. Da kan jeg begynne å få et bilde av hvor bra modelleringsprogrammet faktisk fungerer (jeg har allerede histogrammer fra før jeg implementerte χ2-testen, så nå venter jeg på resultatene fra programmet etter at jeg la til denne). Videre er poenget å gjøre dette for mange ulike varianter av spektre, dvs. spektre hvor de ulike komponentene har forskjellig styrke, og se i hvilken grad dette påvirker hvor godt modelleringsprogrammet klarer å gjette bidragene til spekteret.
Det endelige målet er å kunne sette konkrete tall på når modelleringsprogrammet fungerer. For eksempel: «Modelleringsprogrammet gjør en bra jobb så lenge spekteret inneholder mer enn XX jern, og galaksebidraget er større enn XX prosent, og støynivået er mindre enn XX, osv.»
Det tar dessverre fryktelig lang tid å modellere alle disse spektrene – det tar godt over et døgn å modellere 250 spektre – så jeg har ikke så mange resultater å jobbe med helt ennå. Heldigvis kan jeg kjøre beregningene på en annen server i stedet for på min egen bærbare maskin, for da kan programmet kjøre døgnet rundt uavhengig av meg, og så bare titter jeg innom og ser hvordan det går underveis 🙂



Kommentarer